Version Lifecycle
ICC manages each application version through a lifecycle of three states: Active, Draining, and Expired. This page explains each state and the transitions between them.
The ICC dashboard shows the current state of all versions in the Deployments panel:
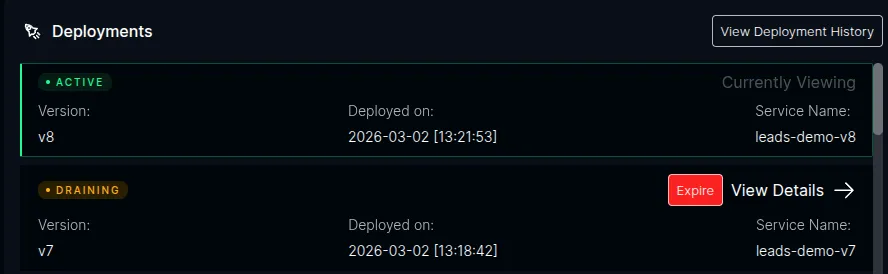
States
Section titled “States”Active
Section titled “Active”The current production version. Exactly one version per application is Active at a time.
- New sessions (visitors without a
__plt_dplcookie) are routed here - The HTTPRoute’s default rule points to this version’s Service
- Responses include a
Set-Cookieheader pinning the session to this version - ICC’s autoscaler scales this Deployment based on real-time load
Draining
Section titled “Draining”A previously active version that still serves existing sessions.
- No new sessions are assigned to it
- Users whose
__plt_dplcookie matches this version continue to be routed here - ICC monitors traffic via Prometheus
- The autoscaler continues scaling this Deployment based on its actual traffic
- A configurable grace period keeps the version alive unconditionally (default: 30 minutes for HTTP)
- A hard max-alive ceiling force-expires the version regardless of remaining traffic (default: 24 hours for HTTP)
Expired
Section titled “Expired”A version that has been fully drained and is no longer serving traffic.
- Its HTTPRoute rules have been removed
- Autoscaling is disabled
- The Deployment is scaled to 0 replicas
- If auto-cleanup is enabled, the Deployment and Service are deleted
State Transitions
Section titled “State Transitions”First Version Detected
Section titled “First Version Detected”When the very first version of an application registers with ICC:
- ICC discovers the pod’s labels and identifies the owning Deployment and Service
- The version is recorded with status Active
- ICC creates an HTTPRoute with a single default rule routing all traffic to this version’s Service
- The
Set-Cookieheader is added to responses, pinning sessions early
New Version Deployed
Section titled “New Version Deployed”When a new version is detected while an Active version exists:
- The new version becomes Active
- The previous Active version transitions to Draining
- ICC updates the HTTPRoute:
- Adds a cookie-match rule for the draining version
- Adds a header-match rule for the draining version (for API clients)
- Updates the default rule to point to the new Active version
Version Expires
Section titled “Version Expires”The draining checker evaluates each draining version on every check interval. It applies a three-phase decision:
- Grace period — while the version has been draining for less than the grace period, it is kept alive unconditionally. No traffic or policy checks are run.
- Policy checks — after the grace period, ICC runs the expire policy for the version. For HTTP traffic this means checking Prometheus for zero RPS. If the policy says the version still has work, it stays alive.
- Max alive — if the version has been draining longer than the max-alive ceiling, it is force-expired regardless of remaining traffic or active work.
A version can also be manually expired by clicking the Expire button in the ICC dashboard, which skips all checks.
When a version expires:
- ICC removes the version’s matching rules from the HTTPRoute
- Autoscaling is disabled for the Deployment
- The Deployment is scaled to 0 replicas
- If auto-cleanup is enabled, the Deployment and Service are deleted
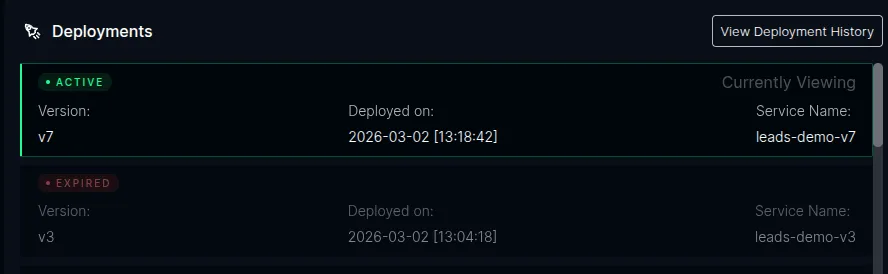
Redeployment of an Expired Version
Section titled “Redeployment of an Expired Version”If a version that was previously expired is redeployed (same plt.dev/version label), ICC re-registers it as Active and updates the routing rules accordingly. This is the rollback flow.
Traffic Monitoring
Section titled “Traffic Monitoring”ICC monitors traffic to draining versions by querying Prometheus for per-version requests per second (RPS):
- Check interval — how often the draining checker runs (default: every 60 seconds, configurable via
PLT_SKEW_CHECK_INTERVAL_MS) - Traffic window — the Prometheus query window for RPS measurement (default: 5 minutes, configurable via
PLT_SKEW_TRAFFIC_WINDOW_MS) - Initial skip — the RPS check is skipped until the version has been draining longer than the traffic window to avoid false zero readings
Grace Period and Max Alive
Section titled “Grace Period and Max Alive”The draining lifecycle is controlled by two time-based thresholds:
- Grace period — after a version enters Draining, it is kept alive unconditionally for this duration. No traffic checks or policy evaluations run during this window. This gives existing sessions time to complete naturally.
- Max alive — the hard ceiling on how long a version can remain in Draining. After this duration, ICC force-expires the version regardless of remaining traffic. This ensures versions are eventually cleaned up even if session tracking is imperfect.
Between the grace period and max alive, ICC runs the expire policy on each check interval to determine whether the version can be expired early (e.g. zero traffic detected).
Both thresholds are configured separately for HTTP and workflow traffic, because workflow runs can take hours or days while HTTP requests complete in seconds:
| Setting | Default | Description |
|---|---|---|
PLT_SKEW_HTTP_GRACE_PERIOD_MS | 1800000 (30 min) | Grace period for HTTP versions |
PLT_SKEW_HTTP_MAX_ALIVE_MS | 86400000 (24h) | Max alive for HTTP versions |
PLT_SKEW_WORKFLOW_GRACE_PERIOD_MS | 3600000 (1h) | Grace period for workflow versions |
PLT_SKEW_WORKFLOW_MAX_ALIVE_MS | 259200000 (72h) | Max alive for workflow versions |
The expire policy is selected per-version based on the plt.dev/workflow label (see below).
See Configuration for all options.
Auto-Cleanup
Section titled “Auto-Cleanup”When a version expires, ICC always scales the Deployment to 0 replicas. Optionally, ICC can also delete the Deployment and Service resources:
- Disabled by default — expired Deployments remain at 0 replicas for users to manually remove
- Enable via
PLT_SKEW_AUTO_CLEANUP=true
Multiple Concurrent Versions
Section titled “Multiple Concurrent Versions”If version v3 is deployed while v1 is still draining (v2 is Active), both v1 and v2 drain simultaneously.
Workflow-Aware Draining
Section titled “Workflow-Aware Draining”Applications that use the Vercel Workflow DevKit with @platformatic/world need special draining behavior. Workflow runs can suspend in ways that are invisible to infrastructure — sleeping, waiting for webhooks, or paused on hooks — with no HTTP traffic and no queue messages.
When a pod has the plt.dev/workflow: "true" label, ICC uses the workflow expire policy instead of the default HTTP policy. This changes two things:
- Separate timings — workflow versions use
PLT_SKEW_WORKFLOW_GRACE_PERIOD_MSandPLT_SKEW_WORKFLOW_MAX_ALIVE_MSinstead of the HTTP equivalents - Active work check — instead of only checking Prometheus RPS, ICC also queries the Workflow Service for active runs, pending hooks, waiting sleeps, and queued messages. The version is kept alive as long as any of these counts are non-zero.
This ensures that a draining version is not expired while workflow runs are still in progress, even if there is zero HTTP traffic to the version’s pods.
Expired Cookie Handling
Section titled “Expired Cookie Handling”When a user returns with a cookie for a version that has been fully expired (HTTPRoute rule removed), the cookie simply doesn’t match any rule. The request falls through to the default rule and is routed to the current production version. The response sets a new cookie, replacing the stale one. No errors occur.